Sometimes, even proper change hygiene can’t prevent issues. If that surprises you, you haven’t been in IT long enough… and recently, we again saw proof of this.
We use Hyper-V as our virtualization platform, managed by SCVMM and monitored by SCOM, using the SCVMM Management Pack. So far, nothing really weird (although I know several VMWare fanatics who would disagree, but let’s skip that part…)
As part of the usual lifecycle management principles, the team responsible for the virtualization and storage decided to replace our classic storage environment by a more software-defined approach involving the new Storage Spaces Direct (S2D) functionality in Windows Server 2016. And that is managed through SCVMM.
Now, SCOM is not a very fast application – and in part, that’s because the SQL side of it is not the most efficient application out there. Basically,if we do not see a deadlock a few times a day, we’re worrying that something is wrong… and if the slowness gets worse, we usually look at the SQL side first.
And that is also what we did when we started getting complaints that SCOM wasn’t just slow, it was completely freezing. Checking the SQL side we saw plenty of indications of resource hogs. Now, I don’t pretend to be a SQL specialist… I just know some very good resources, like Paul Randal’s fantastic blog on Wait Stats and of course, the massive amount of information from Brent Ozar.
We also filed a support case with Microsoft, and after quite some – very well executed – investigations we concluded that both the resources and the configuration of the SCOM database servers should be OK for the workloads. I did get some good suggestions for fine-tuning, but we were sure there were no dramatic underlying issues with AlwaysOn, disk I/O and the likes.
Looking at all the information I had gathered, I couldn’t stop thinking that it must be a previously undiscovered entity – and a big one. And by big, I mean that you’d have a diagram view with thousands of objects. At first, I thought it was our new VDI implementation – if you think of a cluster with several nodes and a few thousand VDI’s, that would classify as a big entity. Fortunately, there’s a good way to disable discovery of the resource groups – check out this blog post. We had that override in place for Server 2012R2, but not yet for Server 2016.
We applied the override, and thought we fixed the problem. But when we checked the next morning, we apparently hadn’t even come close – SCOM was still pretty much frozen. So our journey went on… Using sp_who2 I created a temp table, checking for the head blocker. I then set a SQL Profiler trace on that process, and there was a query that didn’t fire very often but when it did, it went to the absolute top in CPU usage. The query mentioned “DiscoverySourceID”, along with a GUID.
Ever heard of “letting sleeping dogs lie”? Well, there’s a dog in the SCVMM Management Pack. It’s a discovery, called Microsoft.SystemCenter.VirtualMachineManager.Storage.2016.Discovery.Discovery. (Yes, it actually has the word “Discovery” in it twice). And it’s not vicious, it’s downright rabid… think Cujo.
The GUID that i found in the query, led me to the discovery, and the trace showed me the Management Server that the discovery was running on. It fires a Powershell script, that logs event 108. In the OperationsManager eventlog on the Management Server, I then found this:
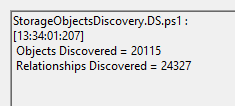
Whoa.
Hang on.
20.000 objects? 24000 relationships?? How many group memberships would that involve? With the recursive memberships??? Like I said, think Cujo… this was a downright horror movie for SQL Server. When that much info is dumped into the OperationsManager database, SQL Server probably simply got traumatized.
Looking through the script, it apparently discovers all storage objects in VMM. And all of their relationships. For more info, check the systemcenter.wiki page…
We disabled the discovery, and then ran Remove-SCOMDisabledClassInstance several times over the course of a few days. Pretty soon, SQL was getting happy again…
From the Microsoft Support case, this was identified as a bug and registered as such. I hope to be able to update this post soon with a fix…
Keep monitoring!